Tables and Data
Tables are where you store your data.
Tables are similar to excel spreadsheets. They contain columns and rows.
For example, this table has 3 "columns" (id, name, description) and 4 "rows" of data:
id | name | description |
|---|---|---|
| 1 | The Phantom Menace | Two Jedi escape a hostile blockade to find allies and come across a young boy who may bring balance to the Force. |
| 2 | Attack of the Clones | Ten years after the invasion of Naboo, the Galactic Republic is facing a Separatist movement. |
| 3 | Revenge of the Sith | As Obi-Wan pursues a new threat, Anakin acts as a double agent between the Jedi Council and Palpatine and is lured into a sinister plan to rule the galaxy. |
| 4 | Star Wars | Luke Skywalker joins forces with a Jedi Knight, a cocky pilot, a Wookiee and two droids to save the galaxy from the Empire's world-destroying battle station. |
There are a few important differences from a spreadsheet, but it's a good starting point if you're new to Relational databases.
Creating tables
When creating a table, it's best practice to add columns at the same time.
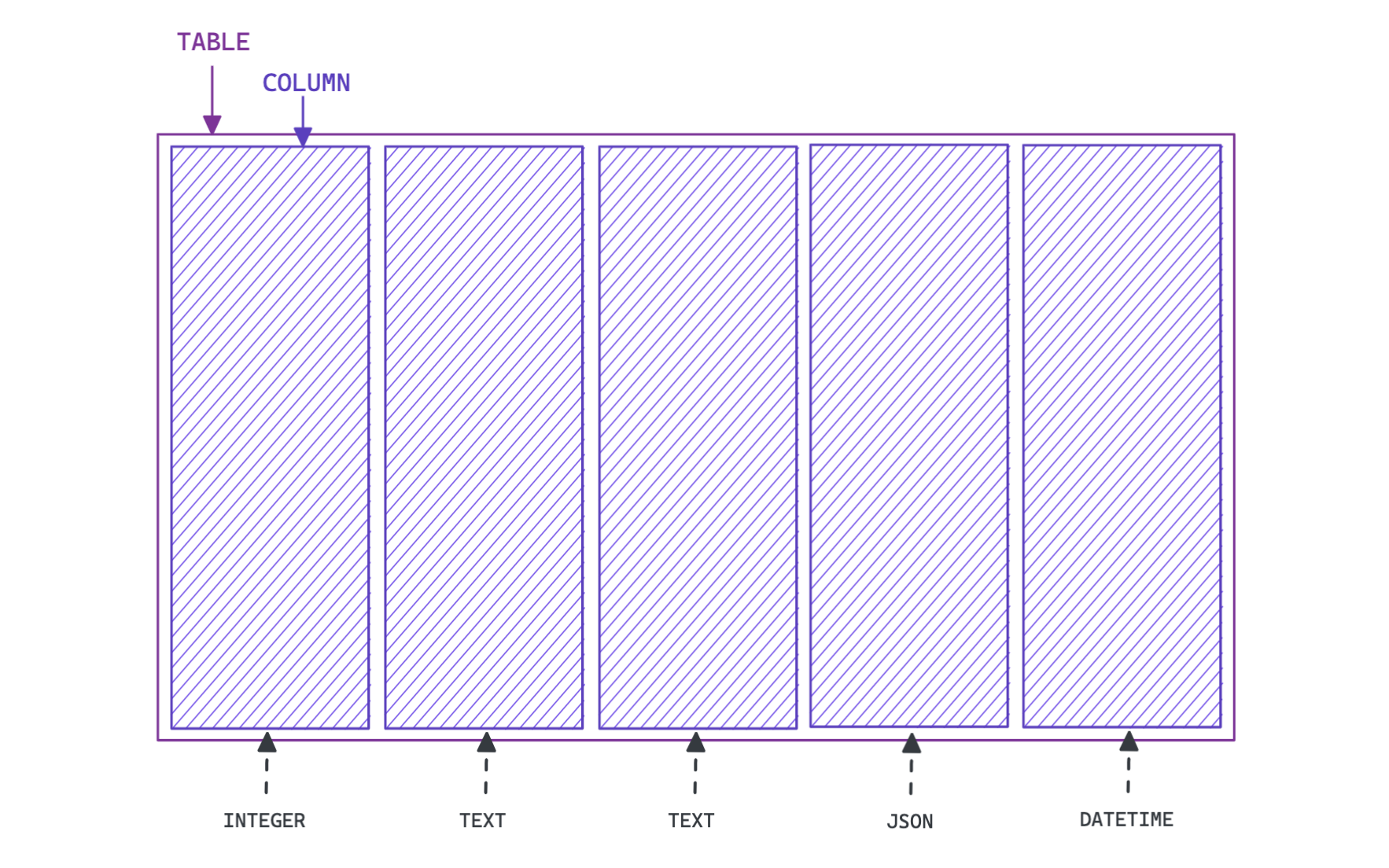
You must define the "data type" of each column when it is created. You can add and remove columns at any time after creating a table.
Supabase provides several options for creating tables. You can use the Dashboard or create them directly using SQL. We provide a SQL editor within the Dashboard, or you can connect to your database and run the SQL queries yourself.
- Go to the Table Editor page in the Dashboard.
- Click New Table and create a table with the name
todos. - Click Save.
- Click New Column and create a column with the name
taskand typetext. - Click Save.
When naming tables, use lowercase and underscores instead of spaces (e.g., table_name, not Table Name).
Columns
You must define the "data type" when you create a column.
Data types
Every column is a predefined type. PostgreSQL provides many default types, and you can even design your own (or use extensions) if the default types don't fit your needs. You can use any data type that Postgres supports via the SQL editor. We only support a subset of these in the Table Editor in an effort to keep the experience simple for people with less experience with databases.
Show/Hide default data types
Name | Aliases | Description |
|---|---|---|
| bigint | int8 | signed eight-byte integer |
| bigserial | serial8 | autoincrementing eight-byte integer |
| bit | fixed-length bit string | |
| bit varying | varbit | variable-length bit string |
| boolean | bool | logical Boolean (true/false) |
| box | rectangular box on a plane | |
| bytea | binary data (“byte array”) | |
| character | char | fixed-length character string |
| character varying | varchar | variable-length character string |
| cidr | IPv4 or IPv6 network address | |
| circle | circle on a plane | |
| date | calendar date (year, month, day) | |
| double precision | float8 | double precision floating-point number (8 bytes) |
| inet | IPv4 or IPv6 host address | |
| integer | int, int4 | signed four-byte integer |
| interval [ fields ] | time span | |
| json | textual JSON data | |
| jsonb | binary JSON data, decomposed | |
| line | infinite line on a plane | |
| lseg | line segment on a plane | |
| macaddr | MAC (Media Access Control) address | |
| macaddr8 | MAC (Media Access Control) address (EUI-64 format) | |
| money | currency amount | |
| numeric | decimal | exact numeric of selectable precision |
| path | geometric path on a plane | |
| pg_lsn | PostgreSQL Log Sequence Number | |
| pg_snapshot | user-level transaction ID snapshot | |
| point | geometric point on a plane | |
| polygon | closed geometric path on a plane | |
| real | float4 | single precision floating-point number (4 bytes) |
| smallint | int2 | signed two-byte integer |
| smallserial | serial2 | autoincrementing two-byte integer |
| serial | serial4 | autoincrementing four-byte integer |
| text | variable-length character string | |
| time [ without time zone ] | time of day (no time zone) | |
| time with time zone | timetz | time of day, including time zone |
| timestamp [ without time zone ] | date and time (no time zone) | |
| timestamp with time zone | timestamptz | date and time, including time zone |
| tsquery | text search query | |
| tsvector | text search document | |
| txid_snapshot | user-level transaction ID snapshot (deprecated; see pg_snapshot) | |
| uuid | universally unique identifier | |
| xml | XML data |
You can "cast" columns from one type to another, however there can be some incompatibilities between types.
For example, if you cast a timestamp to a date, you will lose all the time information that was previously saved.
Primary keys
A table can have a "primary key" - a unique identifier for every row of data. A few tips for Primary Keys:
- It's recommended to create a Primary Key for every table in your database.
- You can use any column as a primary key, as long as it is unique for every row.
- It's common to use a
uuidtype or a numberedidentitycolumn as your primary key.
_10create table movies (_10 id bigint generated always as identity primary key_10);
In the example above, we have:
- created a column called
id - assigned the data type
bigint - instructed the database that this should be
generated always as identity, which means that Postgres will automatically assign a unique number to this column. - Because it's unique, we can also use it as our
primary key.
We could also use generated by default as identity, which would allow us to insert our own unique values.
_10create table movies (_10 id bigint generated by default as identity primary key_10);
Loading data
There are several ways to load data in Supabase. You can load data directly into the database or using the APIs. Use the "Bulk Loading" instructions if you are loading large data sets.
Basic data loading
_11insert into movies_11 (name, description)_11values_11 (_11 'The Empire Strikes Back',_11 'After the Rebels are brutally overpowered by the Empire on the ice planet Hoth, Luke Skywalker begins Jedi training with Yoda.'_11 ),_11 (_11 'Return of the Jedi',_11 'After a daring mission to rescue Han Solo from Jabba the Hutt, the Rebels dispatch to Endor to destroy the second Death Star.'_11 );
Bulk data loading
When inserting large data sets it's best to use PostgreSQL's COPY command. This loads data directly from a file into a table. There are several file formats available for copying data: text, csv, binary, JSON, etc.
For example, if you wanted to load a CSV file into your movies table:
You would connect to your database directly and load the file with the COPY command:
_10psql -h DATABASE_URL -p 5432 -d postgres -U postgres \_10 -c "\COPY movies FROM './movies.csv';"
Additionally use the DELIMITER, HEADER and FORMAT options as defined in the PostgreSQL COPY docs.
_10psql -h DATABASE_URL -p 5432 -d postgres -U postgres \_10 -c "\COPY movies FROM './movies.csv' WITH DELIMITER ',' CSV HEADER"
If you receive an error FATAL: password authentication failed for user "postgres", reset your database password in the Database Settings and try again.
Joining tables with foreign keys
Tables can be "joined" together using Foreign Keys.
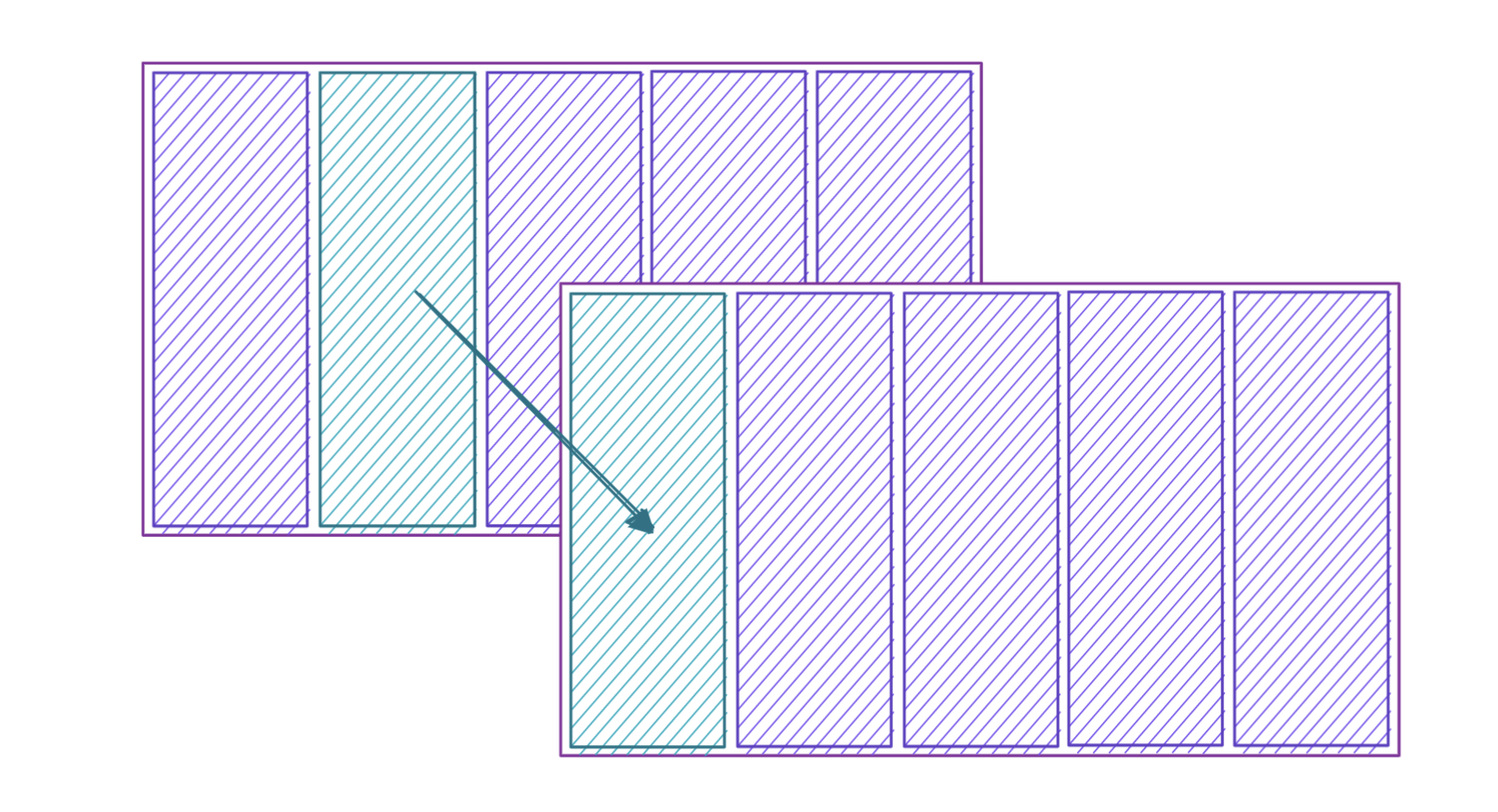
This is where the "Relational" naming comes from, as data typically forms some sort of relationship.
In our "movies" example above, we might want to add a "category" for each movie (for example, "Action", or "Documentary").
Let's create a new table called categories and "link" our movies table.
_10create table categories (_10 id bigint generated always as identity primary key,_10 name text -- category name_10);_10_10alter table movies_10 add column category_id bigint references categories;
You can also create "many-to-many" relationships by creating a "join" table. For example if you had the following situations:
- You have a list of
movies. - A movie can have several
actors. - An
actorcan perform in several movies.
Schemas
Tables belong to schemas. Schemas are a way of organizing your tables, often for security reasons.
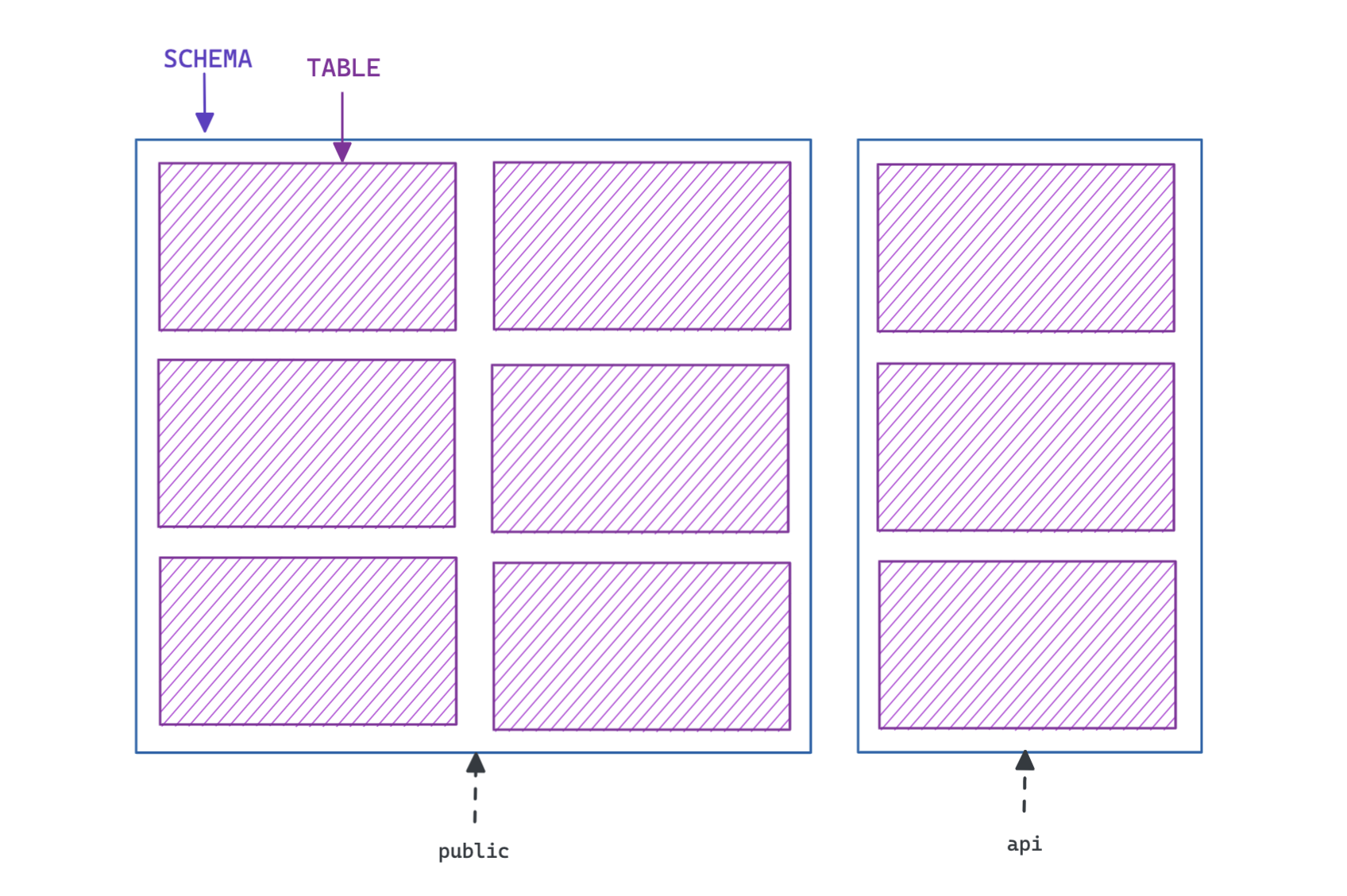
If you don't explicitly pass a schema when creating a table, Postgres will assume that you want to create the table in the public schema.
We can create schemas for organizing tables. For example, we might want a private schema which is hidden from our API:
_10create schema private;
Now we can create tables inside the private schema:
_10create table private.salaries (_10 id bigint generated by default as identity primary key,_10 salary bigint not null,_10 actor_id bigint not null references public.actors_10);
Views
A View is a convenient shortcut to a query. Creating a view does not involve new tables or data. When run, an underlying query is executed, returning its results to the user.
Say we have the following tables from a database of a university:
students
| id | name | type |
|---|---|---|
| 1 | Princess Leia | undergraduate |
| 2 | Yoda | graduate |
| 3 | Anakin Skywalker | graduate |
courses
| id | title | code |
|---|---|---|
| 1 | Introduction to Postgres | PG101 |
| 2 | Authentication Theories | AUTH205 |
| 3 | Fundamentals of Supabase | SUP412 |
grades
| id | student_id | course_id | result |
|---|---|---|---|
| 1 | 1 | 1 | B+ |
| 2 | 1 | 3 | A+ |
| 3 | 2 | 2 | A |
| 4 | 3 | 1 | A- |
| 5 | 3 | 2 | A |
| 6 | 3 | 3 | B- |
Creating a view consisting of all the three tables will look like this:
_12create view transcripts as_12 select_12 students.name,_12 students.type,_12 courses.title,_12 courses.code,_12 grades.result_12 from grades_12 left join students on grades.student_id = students.id_12 left join courses on grades.course_id = courses.id;_12_12alter view transcripts owner to authenticated;
Once done, we can now access the underlying query with:
_10select * from transcripts;
View security
By default, views are accessed with their creator's permission ("security definer"). If a privileged role creates a view, others accessing it will use that role's elevated permissions. To enforce row level security policies, define the view with the "security invoker" modifier.
_10-- alter a security_definer view to be security_invoker_10alter view <view name>_10set (security_invoker = true);_10_10-- create a view with the security_invoker modifier_10create view <view name> with(security_invoker=true) as (_10 select * from <some table>_10);
When to use views
Views provide the several benefits:
- Simplicity
- Consistency
- Logical Organization
- Security
Simplicity
As a query becomes more complex, it can be a hassle to call it over and over - especially when we run it regularly. In the example above, instead of repeatedly running:
_10select_10 students.name,_10 students.type,_10 courses.title,_10 courses.code,_10 grades.result_10from_10 grades_10 left join students on grades.student_id = students.id_10 left join courses on grades.course_id = courses.id;
We can run this instead:
_10select * from transcripts;
Additionally, a view behaves like a typical table. We can safely use it in table JOINs or even create new views using existing views.
Consistency
Views ensure that the likelihood of mistakes decreases when repeatedly executing a query. In our example above, we may decide that we want to exclude the course Introduction to Postgres. The query would become:
_11select_11 students.name,_11 students.type,_11 courses.title,_11 courses.code,_11 grades.result_11from_11 grades_11 left join students on grades.student_id = students.id_11 left join courses on grades.course_id = courses.id_11where courses.code != 'PG101';
Without a view, we would need to go into every dependent query to add the new rule. This would increase in the likelihood of errors and inconsistencies, as well as introducing a lot of effort for a developer. With views, we can alter just the underlying query in the view transcripts. The change will be applied to all applications using this view.
Logical organization
With views, we can give our query a name. This is extremely useful for teams working with the same database. Instead of guessing what a query is supposed to do, a well-named view can easily explain it. For example, by looking at the name of the view transcripts, we can infer that the underlying query might involve the students, courses, and grades tables.
Security
Views can restrict the amount and type of data presented to a user. Instead of allowing a user direct access to a set of tables, we provide them a view instead. We can prevent them from reading sensitive columns by excluding them from the underlying query.
Materialized views
A materialized view is a form of view but it also stores the results to disk. In subsequent reads of a materialized view, the time taken to return its results would be much faster than a conventional view. This is because the data is readily available for a materialized view while the conventional view executes the underlying query each time it is called.
Using our example above, a materialized view can be created like this:
_11create materialized view transcripts as_11 select_11 students.name,_11 students.type,_11 courses.title,_11 courses.code,_11 grades.result_11 from_11 grades_11 left join students on grades.student_id = students.id_11 left join courses on grades.course_id = courses.id;
Reading from the materialized view is the same as a conventional view:
_10select * from transcripts;
Refreshing materialized views
Unfortunately, there is a trade-off - data in materialized views are not always up to date. We need to refresh it regularly to prevent the data from becoming too stale. To do so:
_10refresh materialized view transcripts;
It's up to you how regularly refresh your materialized views, and it's probably different for each view depending on its use-case.
Materialized views vs conventional views
Materialized views are useful when execution times for queries or views are too slow. These could likely occur in views or queries involving multiple tables and billions of rows. When using such a view, however, there should be tolerance towards data being outdated. Some use-cases for materialized views are internal dashboards and analytics.
Creating a materialized view is not a solution to inefficient queries. You should always seek to optimize a slow running query even if you are implementing a materialized view.